Colin Watson: man-db 2.6.0
 I've released man-db 2.6.0 (announcement, NEWS, ChangeLog), and uploaded it to Debian unstable. Ubuntu is rapidly approaching beta freeze so I'm not going to try to cram this into 11.04; it'll be in 11.10.
I've released man-db 2.6.0 (announcement, NEWS, ChangeLog), and uploaded it to Debian unstable. Ubuntu is rapidly approaching beta freeze so I'm not going to try to cram this into 11.04; it'll be in 11.10.
I spent most of last week working on Ubuntu bug 693671 ("wubi install will not boot - phase 2 stops with: Try (hd0,0): NTFS5"), which was quite a challenge to debug since it involved digging into parts of the Wubi boot process I'd never really touched before. Since I don't think much of this is very well-documented, I'd like to spend a bit of time explaining what was involved, in the hope that it will help other developers in the future.
Wubi is a system for installing Ubuntu into a file in a Windows filesystem, so that it doesn't require separate partitions and can be uninstalled like any other Windows application. The purpose of this is to make it easy for Windows users to try out Ubuntu without the need to worry about repartitioning, before they commit to a full installation. Wubi started out as an external project, and initially patched the installer on the fly to do all the rather unconventional things it needed to do; we integrated it into Ubuntu 8.04 LTS, which involved turning these patches into proper installer facilities that could be accessed using preseeding, so that Wubi only needs to handle the Windows user interface and other Windows-specific tasks.
Anyone familiar with a GNU/Linux system's boot process will immediately see that this isn't as simple as it sounds. Of course, ntfs-3g is a pretty solid piece of software so we can handle the Windows filesystem without too much trouble, and loopback mounts are well-understood so we can just have the initramfs loop-mount the root filesystem. Where are you going to get the kernel and initramfs from, though? Well, we used to copy them out to the NTFS filesystem so that GRUB could read them, but this was overly complicated and error-prone. When we switched to GRUB 2, we could instead use its built-in loopback facilities, and we were able to simplify this. So all was more or less well, except for the elephant in the room. How are you going to load GRUB?
In a Wubi installation, NTLDR (or BOOTMGR in Windows Vista and newer) still owns the boot process. Ubuntu is added as a boot menu option using BCDEdit. You might then think that you can just have the Windows boot loader chain-load GRUB. Unfortunately, NTLDR only loads 16 sectors - 8192 bytes - from disk. GRUB won't fit in that: the smallest core.img you can generate at the moment is over 18 kilobytes. Thus, you need something that is small enough to be loaded by NTLDR, but that is intelligent enough to understand NTFS to the point where it can find a particular file in the root directory of a filesystem, load boot loader code from it, and jump to that. The answer for this was GRUB4DOS. Most of GRUB4DOS is based on GRUB Legacy, which is not of much interest to us any more, but it includes an assembly-language program called GRLDR that supports doing this very thing for FAT, NTFS, and ext2. In Wubi, we build GRLDR as
I've released man-db 2.6.0 (announcement, NEWS, ChangeLog), and uploaded it to Debian unstable. Ubuntu is rapidly approaching beta freeze so I'm not going to try to cram this into 11.04; it'll be in 11.10.
I've released man-db 2.6.0 (announcement, NEWS, ChangeLog), and uploaded it to Debian unstable. Ubuntu is rapidly approaching beta freeze so I'm not going to try to cram this into 11.04; it'll be in 11.10.
I spent most of last week working on Ubuntu bug 693671 ("wubi install will not boot - phase 2 stops with: Try (hd0,0): NTFS5"), which was quite a challenge to debug since it involved digging into parts of the Wubi boot process I'd never really touched before. Since I don't think much of this is very well-documented, I'd like to spend a bit of time explaining what was involved, in the hope that it will help other developers in the future.
Wubi is a system for installing Ubuntu into a file in a Windows filesystem, so that it doesn't require separate partitions and can be uninstalled like any other Windows application. The purpose of this is to make it easy for Windows users to try out Ubuntu without the need to worry about repartitioning, before they commit to a full installation. Wubi started out as an external project, and initially patched the installer on the fly to do all the rather unconventional things it needed to do; we integrated it into Ubuntu 8.04 LTS, which involved turning these patches into proper installer facilities that could be accessed using preseeding, so that Wubi only needs to handle the Windows user interface and other Windows-specific tasks.
Anyone familiar with a GNU/Linux system's boot process will immediately see that this isn't as simple as it sounds. Of course, ntfs-3g is a pretty solid piece of software so we can handle the Windows filesystem without too much trouble, and loopback mounts are well-understood so we can just have the initramfs loop-mount the root filesystem. Where are you going to get the kernel and initramfs from, though? Well, we used to copy them out to the NTFS filesystem so that GRUB could read them, but this was overly complicated and error-prone. When we switched to GRUB 2, we could instead use its built-in loopback facilities, and we were able to simplify this. So all was more or less well, except for the elephant in the room. How are you going to load GRUB?
In a Wubi installation, NTLDR (or BOOTMGR in Windows Vista and newer) still owns the boot process. Ubuntu is added as a boot menu option using BCDEdit. You might then think that you can just have the Windows boot loader chain-load GRUB. Unfortunately, NTLDR only loads 16 sectors - 8192 bytes - from disk. GRUB won't fit in that: the smallest core.img you can generate at the moment is over 18 kilobytes. Thus, you need something that is small enough to be loaded by NTLDR, but that is intelligent enough to understand NTFS to the point where it can find a particular file in the root directory of a filesystem, load boot loader code from it, and jump to that. The answer for this was GRUB4DOS. Most of GRUB4DOS is based on GRUB Legacy, which is not of much interest to us any more, but it includes an assembly-language program called GRLDR that supports doing this very thing for FAT, NTFS, and ext2. In Wubi, we build GRLDR as wubildr.mbr, and build a specially-configured GRUB core image as wubildr.
Now, the messages shown in the bug report suggested a failure either within GRLDR or very early in GRUB. The first thing I did was to remember that GRLDR has been integrated into the grub-extras ntldr-img module suitable for use with GRUB 2, so I tried building wubildr.mbr from that; no change, but this gave me a modern baseline to work on. OK; now to try QEMU (you can use tricks like qemu -hda /dev/sda if you're very careful not to do anything that might involve writing to the host filesystem from within the guest, such as recursively booting your host OS ... [update: Tollef Fog Heen and Zygmunt Krynicki both point out that you can use the -snapshot option to make this safer]). No go; it hung somewhere in the middle of NTLDR. Still, I could at least insert debug statements, copy the built wubildr.mbr over to my test machine, and reboot for each test, although it would be slow and tedious. Couldn't I?
Well, yes, I mostly could, but that 8192-byte limit came back to bite me, along with an internal 2048-byte limit that GRLDR allocates for its NTFS bootstrap code. There were only a few spare bytes. Something like this would more or less fit, to print a single mark character at various points so that I could see how far it was getting:
pushal xorw %bx, %bx /* video page 0 */ movw $0x0e4d, %ax /* print 'M' */ int $0x10 popalIn a few places, if I removed some code I didn't need on my test machine (say, CHS compatibility), I could even fit in cheap and nasty code to print a single register in hex (as long as you didn't mind 'A' to 'F' actually being ':' to '?' in ASCII; and note that this is real-mode code, so the loop counter is
%cx not %ecx):
/* print %edx in dumbed-down hex */ pushal xorw %bx, %bx movb $0xe, %ah movw $8, %cx 1: roll $4, %edx movb %dl, %al andb $0xf, %al int $0x10 loop 1b popalAfter a considerable amount of work tracking down problems by bisection like this, I also observed that GRLDR's NTFS code bears quite a bit of resemblance in its logical flow to GRUB 2's NTFS module, and indeed the same person wrote much of both. Since I knew that the latter worked, I could use it to relieve my brain of trying to understand assembly code logic directly, and could compare the two to look for discrepancies. I did find a few of these, and corrected a simple one. Testing at this point suggested that the boot process was getting as far as GRUB but still wasn't printing anything. I removed some Ubuntu patches which quieten down GRUB's startup: still nothing - so I switched my attentions to grub-core/kern/i386/pc/startup.S, which contains the first code executed from GRUB's core image. Code before the first call to
real_to_prot (which switches the processor into protected mode) succeeded, while code after that point failed. Even more mysteriously, code added to real_to_prot before the actual switch to protected mode failed too. Now I was clearly getting somewhere interesting, but what was going on? What I really wanted was to be able to single-step, or at least see what was at the memory location it was supposed to be jumping to.
Around this point I was venting on IRC, and somebody asked if it was reproducible in QEMU. Although I'd tried that already, I went back and tried again. Ubuntu's qemu is actually built from qemu-kvm, and if I used qemu -no-kvm then it worked much better. Excellent! Now I could use GDB:
(gdb) target remote qemu -gdb stdio -no-kvm -hda /dev/sdaThis let me run until the point when NTLDR was about to hand over control, then interrupt and set a breakpoint at
0x8200 (the entry point of startup.S). This revealed that the address that should have been real_to_prot was in fact garbage. I set a breakpoint at 0x7c00 (GRLDR's entry point) and stepped all the way through to ensure it was doing the right thing. In the process it was helpful to know that GDB and QEMU don't handle real mode very well between them. Useful tricks here were:
set architecture i8086 before disassembling real-mode code (and set architecture i386 to switch back).(CS << 4) + IP, rather than just at IP.wubildr correctly and jumping to it. The first instruction it jumped to wasn't in startup.S, though, and then I remembered that we prefix the core image with grub-core/boot/i386/pc/lnxboot.S. Stepping through this required a clear head since it copies itself around and changes segment registers a few times. The interesting part was at real_code_2, where it copies a sector of the kernel to the target load address, and then checks a known offset to find out whether the "kernel" is in fact GRUB rather than a Linux kernel. I checked that offset by hand, and there was the smoking gun. GRUB recently acquired Reed-Solomon error correction on its core image, to allow it to recover from other software writing over sectors in the boot track. This moved the magic number lnxboot.S was checking somewhat further into the core image, after the first sector. lnxboot.S couldn't find it because it hadn't copied it yet! A bit of adjustment and all was well again.
The lesson for me from all of this has been to try hard to get an interactive debugger working. Really hard. It's worth quite a bit of up-front effort if it saves you from killing neurons stepping through pages of code by hand. I think the real-mode debugging tricks I picked up should be useful for working on GRUB in the future.
I spent most of last week working on Ubuntu bug 693671 ("wubi install will not boot - phase 2 stops with: Try (hd0,0): NTFS5"), which was quite a challenge to debug since it involved digging into parts of the Wubi boot process I'd never really touched before. Since I don't think much of this is very well-documented, I'd like to spend a bit of time explaining what was involved, in the hope that it will help other developers in the future.
Wubi is a system for installing Ubuntu into a file in a Windows filesystem, so that it doesn't require separate partitions and can be uninstalled like any other Windows application. The purpose of this is to make it easy for Windows users to try out Ubuntu without the need to worry about repartitioning, before they commit to a full installation. Wubi started out as an external project, and initially patched the installer on the fly to do all the rather unconventional things it needed to do; we integrated it into Ubuntu 8.04 LTS, which involved turning these patches into proper installer facilities that could be accessed using preseeding, so that Wubi only needs to handle the Windows user interface and other Windows-specific tasks.
Anyone familiar with a GNU/Linux system's boot process will immediately see that this isn't as simple as it sounds. Of course, ntfs-3g is a pretty solid piece of software so we can handle the Windows filesystem without too much trouble, and loopback mounts are well-understood so we can just have the initramfs loop-mount the root filesystem. Where are you going to get the kernel and initramfs from, though? Well, we used to copy them out to the NTFS filesystem so that GRUB could read them, but this was overly complicated and error-prone. When we switched to GRUB 2, we could instead use its built-in loopback facilities, and we were able to simplify this. So all was more or less well, except for the elephant in the room. How are you going to load GRUB?
In a Wubi installation, NTLDR (or BOOTMGR in Windows Vista and newer) still owns the boot process. Ubuntu is added as a boot menu option using BCDEdit. You might then think that you can just have the Windows boot loader chain-load GRUB. Unfortunately, NTLDR only loads 16 sectors - 8192 bytes - from disk. GRUB won't fit in that: the smallest core.img you can generate at the moment is over 18 kilobytes. Thus, you need something that is small enough to be loaded by NTLDR, but that is intelligent enough to understand NTFS to the point where it can find a particular file in the root directory of a filesystem, load boot loader code from it, and jump to that. The answer for this was GRUB4DOS. Most of GRUB4DOS is based on GRUB Legacy, which is not of much interest to us any more, but it includes an assembly-language program called GRLDR that supports doing this very thing for FAT, NTFS, and ext2. In Wubi, we build GRLDR as wubildr.mbr, and build a specially-configured GRUB core image as wubildr.
Now, the messages shown in the bug report suggested a failure either within GRLDR or very early in GRUB. The first thing I did was to remember that GRLDR has been integrated into the grub-extras ntldr-img module suitable for use with GRUB 2, so I tried building wubildr.mbr from that; no change, but this gave me a modern baseline to work on. OK; now to try QEMU (you can use tricks like qemu -hda /dev/sda if you're very careful not to do anything that might involve writing to the host filesystem from within the guest, such as recursively booting your host OS ...). No go; it hung somewhere in the middle of NTLDR. Still, I could at least insert debug statements, copy the built wubildr.mbr over to my test machine, and reboot for each test, although it would be slow and tedious. Couldn't I?
Well, yes, I mostly could, but that 8192-byte limit came back to bite me, along with an internal 2048-byte limit that GRLDR allocates for its NTFS bootstrap code. There were only a few spare bytes. Something like this would more or less fit, to print a single mark character at various points so that I could see how far it was getting:
pushal xorw %bx, %bx /* video page 0 */ movw $0x0e4d, %ax /* print 'M' */ int $0x10 popalIn a few places, if I removed some code I didn't need on my test machine (say, CHS compatibility), I could even fit in cheap and nasty code to print a single register in hex (as long as you didn't mind 'A' to 'F' actually being ':' to '?' in ASCII; and note that this is real-mode code, so the loop counter is
%cx not %ecx):
/* print %edx in dumbed-down hex */ pushal xorw %bx, %bx movb $0xe, %ah movw $8, %cx 1: roll $4, %edx movb %dl, %al andb $0xf, %al int $0x10 loop 1b popalAfter a considerable amount of work tracking down problems by bisection like this, I also observed that GRLDR's NTFS code bears quite a bit of resemblance in its logical flow to GRUB 2's NTFS module, and indeed the same person wrote much of both. Since I knew that the latter worked, I could use it to relieve my brain of trying to understand assembly code logic directly, and could compare the two to look for discrepancies. I did find a few of these, and corrected a simple one. Testing at this point suggested that the boot process was getting as far as GRUB but still wasn't printing anything. I removed some Ubuntu patches which quieten down GRUB's startup: still nothing - so I switched my attentions to grub-core/kern/i386/pc/startup.S, which contains the first code executed from GRUB's core image. Code before the first call to
real_to_prot (which switches the processor into protected mode) succeeded, while code after that point failed. Even more mysteriously, code added to real_to_prot before the actual switch to protected mode failed too. Now I was clearly getting somewhere interesting, but what was going on? What I really wanted was to be able to single-step, or at least see what was at the memory location it was supposed to be jumping to.
Around this point I was venting on IRC, and somebody asked if it was reproducible in QEMU. Although I'd tried that already, I went back and tried again. Ubuntu's qemu is actually built from qemu-kvm, and if I used qemu -no-kvm then it worked much better. Excellent! Now I could use GDB:
(gdb) target remote qemu -gdb stdio -no-kvm -hda /dev/sdaThis let me run until the point when NTLDR was about to hand over control, then interrupt and set a breakpoint at
0x8200 (the entry point of startup.S). This revealed that the address that should have been real_to_prot was in fact garbage. I set a breakpoint at 0x7c00 (GRLDR's entry point) and stepped all the way through to ensure it was doing the right thing. In the process it was helpful to know that GDB and QEMU don't handle real mode very well between them. Useful tricks here were:
set architecture i8086 before disassembling real-mode code (and set architecture i386 to switch back).(CS << 4) + IP, rather than just at IP.wubildr correctly and jumping to it. The first instruction it jumped to wasn't in startup.S, though, and then I remembered that we prefix the core image with grub-core/boot/i386/pc/lnxboot.S. Stepping through this required a clear head since it copies itself around and changes segment registers a few times. The interesting part was at real_code_2, where it copies a sector of the kernel to the target load address, and then checks a known offset to find out whether the "kernel" is in fact GRUB rather than a Linux kernel. I checked that offset by hand, and there was the smoking gun. GRUB recently acquired Reed-Solomon error correction on its core image, to allow it to recover from other software writing over sectors in the boot track. This moved the magic number lnxboot.S was checking somewhat further into the core image, after the first sector. lnxboot.S couldn't find it because it hadn't copied it yet! A bit of adjustment and all was well again.
The lesson for me from all of this has been to try hard to get an interactive debugger working. Really hard. It's worth quite a bit of up-front effort if it saves you from killing neurons stepping through pages of code by hand. I think the real-mode debugging tricks I picked up should be useful for working on GRUB in the future.
#!/usr/bin/make -f
# Uncomment this to turn on verbose mode.
#export DH_VERBOSE=1
include /usr/share/cdbs/1/rules/debhelper.mk
include /usr/share/cdbs/1/class/qmake.mk
DEB_QMAKE_CONFIG_VAL += build64
DEB_QMAKE_ARGS = qcs.pro
build/qutecsound::
[ -f bin/qutecsound ] mv bin/qutecsound-d bin/qutecsound
clean::
rm -f bin/qutecsound
QMAKE = qmake-qt4
DEB_BUILD_PARALLEL = 1
DEB_INSTALL_MANPAGES_qutecsound = debian/qutecsound.1
#!/usr/bin/make -f
# Uncomment this to turn on verbose mode.
#export DH_VERBOSE=1
include /usr/share/cdbs/1/rules/debhelper.mk
include /usr/share/cdbs/1/class/qmake.mk
QMAKE = qmake-qt4
DEB_QMAKE_CONFIG_VAL += build64
DEB_QMAKE_ARGS = qcs.pro
DEB_BUILD_PARALLEL = 1
DEB_INSTALL_MANPAGES_qutecsound = debian/qutecsound.1
build/qutecsound::
[ -f bin/qutecsound ] mv bin/qutecsound-d bin/qutecsound
clean::
rm -f bin/qutecsound
I've released libpipeline 1.1.0, and uploaded it to Debian unstable. The changes are mostly just to add a few occasionally useful interfaces:
pipecmd_exec to execute a single command, replacing the current process; this is analogous to execvp.pipecmd_clearenv to clear a command's environment; this is analogous to clearenv.pipecmd_get_nargs to get the number of arguments to a command. As I mentioned recently, the Ubuntu Technical Board is reviewing the most popular topics in Ubuntu Brainstorm and coordinating official responses on behalf of the project. This means that the most popular topics on Ubuntu Brainstorm receive expert answers from the people working in these areas.
This is the first batch, and we plan to repeat this process each quarter. We ll use feedback and experiences from this run to improve it for next time, so let us know what you think.
Power management (idea #24782)
Laptops are now outselling desktops globally, and laptop owners want to get the most out of their expensive and heavy batteries. So it s no surprise that people are wondering about improved power management in Ubuntu. This is a complex topic which spans the Linux software stack, and certainly isn t an issue which will be solved in the foreseeable future, but we see a lot of good work being done in this area.
To tell us about it, Amit Kucheria, Ubuntu kernel developer and leader of the Linaro working group on Power Management, contributed a great writeup on this topic, with technical analysis, tips and recommendations, and a look at what s coming next.
As I mentioned recently, the Ubuntu Technical Board is reviewing the most popular topics in Ubuntu Brainstorm and coordinating official responses on behalf of the project. This means that the most popular topics on Ubuntu Brainstorm receive expert answers from the people working in these areas.
This is the first batch, and we plan to repeat this process each quarter. We ll use feedback and experiences from this run to improve it for next time, so let us know what you think.
Power management (idea #24782)
Laptops are now outselling desktops globally, and laptop owners want to get the most out of their expensive and heavy batteries. So it s no surprise that people are wondering about improved power management in Ubuntu. This is a complex topic which spans the Linux software stack, and certainly isn t an issue which will be solved in the foreseeable future, but we see a lot of good work being done in this area.
To tell us about it, Amit Kucheria, Ubuntu kernel developer and leader of the Linaro working group on Power Management, contributed a great writeup on this topic, with technical analysis, tips and recommendations, and a look at what s coming next.
I am going to attempt to summarize the various use profiles and what Ubuntu does (or can do) to prolong battery life in those profiles. Power management, when done right, should not require the user to make several (difficult) choices. It should just work providing a good balance of performance and battery life.IP address conflicts (idea #25648) IP addressing is a subject that most people should never have to think about. When something isn t working, and two computers end up with the same IP address, it can be hard to tell what s wrong. I was personally surprised to find this one near the top of the list on Ubuntu Brainstorm, since it seems unlikely to be a very common problem. Nonetheless, it was voted up, and we re listening. There is a tool called ipwatchd which is already available in the package repository, and was created specifically to address this problem. This seems like a further indication that this problem may be more widespread than I might assume. The idea has already been marked as implemented in Brainstorm based on the existence of this package, but that doesn t help people who have never heard of ipwatchd, much less found and installed it. What do you think? Have you ever run into this problem? Would it have helped you if your computer had told you what was wrong, or would it have only confused you further? Is it worth considering this for inclusion in the default install? Post your comments in Brainstorm. Selecting the only available username to login (idea #6974) Although Linux is designed as a multi-user operating system, most Ubuntu systems are only used by one person. In that light, it seems a bit redundant to ask the user to identify themselves every time they login, by clicking on their username. Why not just preselect it? Indeed, this would be relatively simple to implement, but the real question is whether it is the right choice for users. Martin Pitt of the Ubuntu Desktop Team notes that consistency is an important factor in ease of use, and asks for further feedback.
So in summary, we favored consistency and predictablility over the extra effort to press Enter once. This hasn t been a very strong opinion or decision, though, and the desktop team would be happy to revise it.Icon for .deb packages (idea #25197) Building on the invaluable efforts of Debian developers, we work hard to make sure that people can get all of the software they need from Ubuntu repositories through Software Center and APT, where they are authenticated and secure. However, in practice, it is occasionally necessary for users to work with .deb files directly. Brainstorm idea 25197 suggests that the icon used to represent .deb packages in the file manager is not ideal, and can be confusing. Matthew Paul Thomas of the Canonical Design Team responds with encouragement for deb-thumbnailer, which makes the icon both more distinctive and more informative. He has opened bug 685851 to track progress on getting it packaged and into the main repository.
I have reviewed the proposed solutions with Michael Vogt, our packaging expert. Solution #1 is straightforward, but we particularly like solutions #5 and #10, using a thumbnailer to show the application icon from inside each package.Keeping the time accurate over the Internet by default (idea #25301) It s important for an Internet connected computer to know the correct time of day, which is why Ubuntu has included automatic Internet time synchronization with NTP since the very first release (4.10 warty ). So some of us were a little surprised to see this as one of the most popular ideas on Ubuntu Brainstorm. Colin Watson of the Ubuntu Technical Board investigated and discovered a case where this wasn t working correctly. It s now fixed for Ubuntu 11.04, and Colin has sent the patches upstream to Debian and GNOME.
My first reaction was hey, that s odd I thought we already did that? . We install the ntpdate package by default (although it s deprecated upstream in favour of other tools, but that shouldn t be important here). ntpdate is run from /etc/network/if-up.d/ntpdate, in other words every time you connect to a network, which should be acceptably frequent for most people, so it really ought to Just Work by default. But this is one of the top ten problems where users have gone to the trouble of proposing solutions on Brainstorm, so it couldn t be that simple. What was going on?More detail in GNOME system monitor (idea #25887) Under System, Preferences, System Monitor, you can find a tool to peek under the hood at the Linux processes which power every Ubuntu system. Power users, hungry for more detail on their systems inner workings, voted to suggest that more detail be made available through this interface. Robert Ancell of the Ubuntu Desktop Team answered their call by offering to mentor a volunteer to develop a patch, and someone has already stepped up with a first draft. Help the user understand when closing a window does not close the app (idea #25801) When the user clicks the close button, most applications obediently exit. A few, though, will just hide, and continue running, because they assume that s what the user actually wants, and it can be hard to tell which has happened. Ivanka Majic, Creative Strategy Lead at Canonical, shares her perspective on this issue, with a pointer to work in progress to resolve it.
This is more than a good idea, it s an important gap in the usability of most of the desktop operating systems in widespread use today.Ubuntu Software Centre Removal of Configuration Files (idea #24963) One feature of the Debian packaging system used in Ubuntu is that it draws a distinction between removing a package and purging it. Purging should remove all traces of the package, such that installing and then immediately purging a package should return the system to the same state. Removing will leave certain files behind, including system configuration files and sometimes runtime data. This subtle distinction is useful to system administrators, but only serves to confuse most end users, so it s not exposed by Software Center: it just defaults to removing packages. This proposal in Ubuntu Brainstorm suggests that Software Center should purge packages by default instead. Michael Vogt of the Ubuntu Foundations Team explains the reasoning behind this default, and offers an alternative suggestion based on his experience with the package management system.
This is not a easy problem and we need to carefully balance the needs to keep the UI simple with the needs to keep the system from accumulating cruft.Ubuntu One file sync progress (idea #25417) Ubuntu One file synchronization works behind the scenes, uploading and downloading as needed to replicate your data to multiple computers. It does most of its work silently, and it can be hard to tell what it is doing or when it will be finished. John Lenton, engineering manager for the Ubuntu One Desktop+ team, posts on the AskUbuntu Q&A site with tools and tips which work today, and their plans to address this issue comprehensively in the future. Multimedia performance (idea #24878) With a cornucopia of multimedia content available online today, it s important that users be able to access it quickly and easily. Poor performance in the audio, video and graphics subsystems can spoil the experience, if resource-hungry multimedia applications can t keep up with the flow of data. Allison Randal, Ubuntu Technical Architect, answers with an analysis of the problem and the proposed solutions, an overview of current activity in this area, and pointers for getting involved.
The fundamental concern is a classic one for large systems: changes in one part of the system affect the performance of another part of the system. It s modestly difficult to measure the performance effects of local changes, but exponentially more difficult to measure the network effects of changes across the system.






 The Ubuntu Technical Board is currently conducting a review of the top ten Brainstorm issues users have raised about Ubuntu, and Matt asked me to investigate and respond to Idea #25301: Keeping the time accurate over the Internet by default.
My first reaction was "hey, that's odd - I thought we already did that?". We install the
The Ubuntu Technical Board is currently conducting a review of the top ten Brainstorm issues users have raised about Ubuntu, and Matt asked me to investigate and respond to Idea #25301: Keeping the time accurate over the Internet by default.
My first reaction was "hey, that's odd - I thought we already did that?". We install the ntpdate package by default (although it's deprecated upstream in favour of other tools, but that shouldn't be important here). ntpdate is run from /etc/network/if-up.d/ntpdate, in other words every time you connect to a network, which should be acceptably frequent for most people, so it really ought to Just Work by default. But this is one of the top ten problems where users have gone to the trouble of proposing solutions on Brainstorm, so it couldn't be that simple. What was going on?
I brought up a clean virtual machine with a development version of Natty (the current Ubuntu development version, which will eventually become 11.04), and had a look in its logs: it was indeed synchronising its time from ntp.ubuntu.com, and I didn't think anything in that area had changed recently. On the other hand, I had occasionally noticed that my own laptop wasn't always synchronising its time quite right, but I'd put it down to local weirdness as my network isn't always very stable. Maybe this wasn't so local after all?
So, I started tracing through the scripts to figure out what was going on. It turned out that I had an empty /etc/ntp.conf file on my laptop. The /usr/sbin/ntpdate-debian script assumed that that meant I had a full NTP server installed (I don't), and fetched the list of servers from it; since the file was empty, it ended up synchronising time from no servers, that is, not synchronising at all. I removed the file and all was well.
That left the question of where that file came from. It didn't seem to be owned by any package; I was pretty sure I hadn't created it by hand either. I had a look through some bug reports, and soon found ntpdate 1:4.2.2.p4+dfsg-1ubuntu2 has a flawed configuration file. It turns out that time-admin (System -> Administration -> Time and Date) creates an empty /etc/ntp.conf file if you press the reload button (tooltip: "Synchronise now"), as part of an attempt to update NTP configuration. Aha!
Once I knew where the problems were, it was easy to fix them. I've uploaded the following changes, which will be in the 11.04 release:
ntp.conf files in ntpdate-debian./etc/ntp.conf file on fresh installation of the ntp package, so that it doesn't interfere with creating the normal configuration file.time-admin backend if it doesn't exist already.ntp.ubuntu.com then you'll have to change the value of NTPSERVERS in /etc/default/ntpdate. Furthermore, the time-admin interface is confusing and makes it seem as though the default is not to synchronise the time automatically; this interface is being redesigned at the moment, which should be a good opportunity to make it less confusing, and I will contact the designers to mention this problem. On the whole, though, I think that many fewer people should have this kind of problem in Ubuntu 11.04.
It's always possible that I missed some other problem that breaks automatic time synchronisation for people. Please do file a bug report if it still doesn't work for you in 11.04, or contact me directly (cjwatson at ubuntu.com).
I just found out by chance that Fedora 14 switched from their old man package to man-db. This is great news: it should now be the beginning of the end of the divergence of man implementations that happened way back in the mid-1990s, when two different people took John W. Eaton's man package and developed it in different directions without being aware of each other's existence. For a while it looked as though man-db was stuck on just the Debian family and openSUSE, but a number of distributions have switched over in the last few years. As of now, the only remaining major distribution not using man-db is Gentoo, and they have a bug for switching which I think should be unblocked fairly soon.
In some ways man-db's package name didn't help it; people thought that the main difference was that man-db had a database backend stuck around apropos. These days, the database is one of the least important parts of man-db as far as I'm concerned. Other ways in which it's very significantly superior to anything man could do without years of equivalent effort include correct encoding support, robust child process handling, and use of more modern development facilities (dear catgets: you belong to a previous millennium, so please go away). I'm glad that Fedora has recognised this.
In my previous post, I described the pipeline library from man-db and asked whether people were interested in a standalone release of it. Several people expressed interest, and so I've now released libpipeline version 1.0.0. It's in the Debian NEW queue, and my PPA contains packages of it for Ubuntu lucid and maverick.
I gave a lightning talk on this at UDS in Orlando, and my slides are available. I hope there'll be a video at some point which I can link to.
Thanks to Scott James Remnant for code review (some time back), Ian Jackson for an extensive design review, and Kees Cook and Matthias Klose for helpful conversations.
When I took over man-db in 2001, one of the major problems that became evident after maintaining it for a while was the way it handled subprocesses. The nature of man and friends means that it spends a lot of time calling sequences of programs such as zsoelim < input-file tbl nroff -mandoc -Tutf8. Back then, it was using C library facilities such as system and popen for all this, and I had to deal with several bugs where those functions were being called with untrusted input as arguments without properly escaping metacharacters. Of course it was possible to chase around every such call inserting appropriate escaping functions, but this was always bound to be error-prone and one of the tasks that rapidly became important to me was arranging to start subprocesses in a way that was fundamentally immune to this kind of bug.
In higher-level languages, there are usually standard constructs which are safer than just passing a command line to the shell. For example, in Perl you can use system([$command, $arg1, $arg2, ...]) to invoke a program with arguments without the interference of the shell, and perlipc(1) describes various facilities for connecting them together. In Python, the subprocess module allows you to create pipelines easily and safely (as long as you remember the SIGPIPE gotcha). C has the fork and execve primitives, but assembling these to construct full-blown pipelines correctly is difficult and error-prone, so many programmers don't bother and use the simple but unsafe library facilities instead.
I wrote a couple of thousand lines of library code in man-db to address this problem, loosely and now quite distantly based on code in groff. In the following examples, function names starting with command_, pipeline_, or decompress_ are real functions in the library, while any other function names are pseudocode.
Constructing the simplified example pipeline from my first paragraph using this library looks like this:
pipeline *p; int status; p = pipeline_new (); p->want_infile = "input-file"; pipeline_command_args (p, "zsoelim", NULL); pipeline_command_args (p, "tbl", NULL); pipeline_command_args (p, "nroff", "-mandoc", "-Tutf8", NULL); pipeline_start (p); status = pipeline_wait (p); pipeline_free (p);You might want to construct a command more dynamically:
command *manconv = command_new_args ("manconv", "-f", from_code,
"-t", "UTF-8", NULL);
if (quiet)
command_arg (manconv, "-q");
pipeline_command (p, manconv);
Perhaps you want an environment variable set only while running a certain command:
command *less = command_new ("less");
command_setenv (less, "LESSCHARSET", lesscharset);
You might find yourself needing to pass the output of one pipeline to several other pipelines, in a "tee" arrangement:
pipeline *source, *sink1, *sink2; source = make_source (); sink1 = make_sink1 (); sink2 = make_sink2 (); pipeline_connect (source, sink1, sink2, NULL); /* Pump data among these pipelines until there's nothing left. */ pipeline_pump (source, sink1, sink2, NULL); pipeline_free (sink2); pipeline_free (sink1); pipeline_free (source);Maybe one of your commands is actually an in-process function, rather than an external program:
command *inproc = command_new_function ("in-process", &func, NULL, NULL);
pipeline_command (p, inproc);
Sometimes your program needs to consume the output of a pipeline, rather than sending it all to some other subprocess:
pipeline *p = make_pipeline ();
const char *line;
line = pipeline_peekline (p);
if (!strstr (line, "coding: UTF-8"))
printf ("Unicode text follows:\n");
while (line = pipeline_readline (p))
printf (" %s", line);
pipeline_free (p);
man-db deals with compressed files a lot, so I wrote an add-on library for opening compressed files (which is somewhat man-db-specific, but the implementation wasn't difficult given the underlying library):
pipeline *decomp_file = decompress_open (compressed_filename); pipeline *decomp_stdin = decompress_fdopen (fileno (stdin));This library has been in production in man-db for over five years now. The very careful signal handling code has been reviewed independently and the whole thing has been run through multiple static analysis tools, although I would always welcome more review; in particular I have no idea what it would take to make it safe for use in threaded programs since I generally avoid threading wherever possible. There have been a handful of bugs, which I've fixed promptly, and I've added various new features to support particular requirements of man-db (though in as general a way as possible). Every so often I see somebody asking about subprocess handling in C, and I wonder if I should split this library out into a standalone package so that it can be used elsewhere. Web searches for things like "pipeline library" and "libpipeline" don't reveal anything that's a particularly close match for what I have. The licensing would be GPLv2 or later; this isn't likely to be negotiable since some of the original code wasn't mine and in any case I don't feel particularly bad about giving an advantage to GPLed programs. For more details on the interface, the header file is well-commented. Is there enough interest in this to make the effort of producing a separate library package worthwhile? As well as the general effort of creating a new package, I'd need to do some work to disentangle it from a few bits and pieces specific to man-db. If you maintain a specific package that could use this and you're interested, please contact me with details, mentioning any extensions you think you'd need. I intentionally haven't enabled comments on my blog for various reasons, but you can e-mail me at cjwatson at debian.org or man-db-devel at nongnu.org.
If you find that running Windows makes a GRUB 2-based system unbootable (Debian bug, Ubuntu bug), then I'd like to hear from you. This is a bug in which some proprietary Windows-based software overwrites particular sectors in the gap between the master boot record and the first partition, sometimes called the "embedding area". GRUB Legacy and GRUB 2 both normally use this part of the disk to store one of their key components: GRUB Legacy calls this component Stage 1.5, while GRUB 2 calls it the core image (comparison). However, Stage 1.5 is less useful than the core image (for example, the latter provides a rescue shell which can be used to recover from some problems), and is therefore rather smaller: somewhere around 10KB vs. 24KB for the common case of ext[234] on plain block devices. It seems that the Windows-based software writes to a sector which is after the end of Stage 1.5, but before the end of the core image. This is why the problem appears to be new with GRUB 2.
At least some occurrences of this are with software which writes a signature to the embedding area which hangs around even after uninstallation (even with one of those tools that tracks everything the installation process did and reverses it, I gather), so that you cannot uninstall and reinstall the application to defeat a trial period. This seems like a fine example of an antifeature, especially given its destructive consequences for free software, and is in general a poor piece of engineering; what happens if multiple such programs want to use the same sector, I wonder? They clearly aren't doing much checking that the sector is unused, not that that's really possible anyway. While I do not normally think that GRUB should go to any great lengths to accommodate proprietary software, this is a case where we need to defend ourselves against the predatory practices of some companies making us look bad: a relatively small number of people do enough detective work to realise that it's the fault of a particular Windows application, but many more simply blame our operating system because it won't start any more.
I believe that it may be possible to assemble a collection of signatures of such software, and arrange to avoid the disk sectors they have stolen. Indeed, I have a first draft of the necessary code. This is not a particularly pleasant solution, but it seems to be the most practical way around the problem; I'm hoping that several of the programs at fault are using common "licence manager" code or something like that, so that we can address most of the problems with a relatively small number of signatures. In order to do this, I need to hear from as many people as possible who are affected by this problem.
If you suffer from this problem, then please do the following:
fdisk -lu to a file. In this output, take note of the start sector of the first partition (usually 63, but might also be 2048 on recent installations, or occasionally something else). If this is something other than 63, then replace 63 in the following items with your number./dev/sda with your disk device if it's something else): dd if=/dev/sda of=sda.1 count=63dd if=/dev/sda of=sda.2 count=63fdisk -lu, and the embedding area before and after making GRUB unbootable.#debian-bugs.
Get involved, it starts today, and it's
open to everyone (DebConf10 attendees as well as
Debian enthusiasts abroad, regular RC squashers as well as casual
bystanders, etc).
All this wouldn't have been possible without the help of many
people that love Debian, so many thanks to:
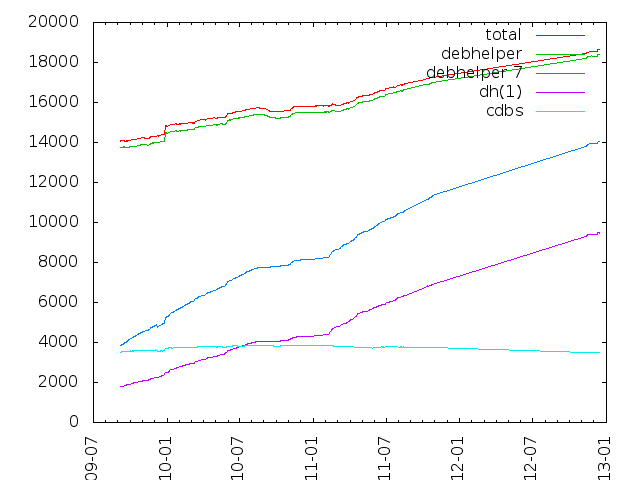
Apropos of my previous post, I see that dh has now overtaken CDBS as the most popular rules helper system of its kind in Debian unstable, and shows no particular sign of slowing its rate of uptake any time soon. The resolution of the graph is such that you can't see it yet, but dh drew dead level with CDBS on Thursday, and today 3836 packages are using dh as opposed to 3823 using CDBS.
 ... this version, or something not too far away from it, might actually stand a chance of getting into testing.
I've just uploaded grub2 1.98+20100702-1. The most significant set of changes in this release is that it switches
... this version, or something not too far away from it, might actually stand a chance of getting into testing.
I've just uploaded grub2 1.98+20100702-1. The most significant set of changes in this release is that it switches /boot/grub/device.map and the grub-pc/install_devices debconf question over to stable device names under /dev/disk/by-id (on Linux kernels). The code implementing this is reasonably careful, and it should make it quite difficult for people to accidentally fail to upgrade their installed GRUB core image; I explained the problems that tends to cause in the previous post in this series. There will probably be a few small glitches I need to clear up, but I've given this much more extensive testing than usual so I hope I won't break too many people's computers (again).
I did this work first in Ubuntu as one of my major goals for 10.04 LTS, which exposed a few problems that I wanted to fix before inflicting it on Debian as well (fixes for those are now under testing for 10.04.1). Most significantly, I felt it was necessary to start offering partitions in the select list for grub-pc/install_devices, but I went a bit overboard and offered all partitions in a giant list. This seemed like a good idea at the time, but it tended to confuse people into just selecting everything in the list, which in particular tended to make Windows unbootable! So I dialled that back a bit, and in the version I just merged it will only offer the partitions mounted on /, /boot, and /boot/grub (de-duplicating if necessary). This seems like a reasonable compromise between confusing people too much and forcing them to install only to MBRs.
My next priority will be making whatever fixes are necessary to get this version into testing, since the problems with /dev/mapper symlinks in testing aren't getting any less urgent, and this is finally a version that shouldn't break for most people due to the kernel's switch to libata. I expect that I'll try to get mdadm 1.x metadata sorted out immediately after that.
Other improvements since my last entry have included:
device.map, and (shortly) a summary of changes from GRUB Legacy. (This is partly a repost of material I've posted to bug reports and to debian-release, put together with some more detail for a wider audience.)
You could be forgiven for looking at the RC bug activity on grub2 over the last couple of days and thinking that it's all gone to hell in a handbasket with recent uploads. In fact, aside from an interesting case which turned out to be due to botched handling of the GRUB Legacy to GRUB 2 chainloading setup (which prompted me to fix three other RC bugs along the way), all the recent problems people have been having have been duplicates of one of these bugs which have existed essentially forever:
upgrade-from-grub-legacy once you confirmed it worked, and then later ran grub-install by hand for one reason or another, then the core image you installed by hand would never be updated and would eventually fall over the next time the core/modules interface changed. Fixing future cases of this was easy enough, but fixing existing cases involved figuring out how to detect whether an installed GRUB boot sector came from GRUB Legacy or GRUB 2, which isn't as easy as you might think. Fortunately, it turns out that there are a limited number of jump offsets that have ever been used in the second byte of the boot sector, and none of the GRUB 2 values clash with the only value ever used in GRUB Legacy; so, if you still have /boot/grub/stage2 et al on upgrade, we scan all disks for a GRUB 2 boot sector, and if we find one then we offer to complete the upgrade to GRUB 2.
Unless anything new shows up, that just leaves the problems that were already understood. Today, I posted a patch to generate stable device names in device.map by default. If this is accepted, then we can do something or other to fix up device.map on upgrade, switch over to /dev/disk/by-id names in grub-pc/install_devices at the same time, and that should take care of the vast majority of this kind of upgrade bug. I think at that point it should be feasible to get a new version into testing, and we should be down from 18 RC bugs towards the end of last month to around 6. We can then start attacking things like the lack of support for mdadm 1.x metadata.
Since my last blog entry on GRUB 2, improvements have included:
info grub, with, among other things, new sections on /etc/default/grub and on configuring authentication.fs.lst, partmap.lst, and video.lst, which should speed up booting a bit by e.g. avoiding unnecessary filesystem probing.upgrade-from-grub-legacy actually now installs GRUB 2 to the boot sector (!).grub-pc/install_devices is left empty.grub-install actually work on UEFI systems as one of my goals for the next Ubuntu release, and I hope to get this landed in the not-too-distant future.
Various people observed in a long thread on debian-devel that the grub2 package was in a bit of a mess in terms of its release-critical bug count, and Jordi and Stefano both got in touch with me directly to gently point out that I probably ought to be doing something about it as one of the co-maintainers.
Actually, I don't think grub2 was in quite as bad a state as its 18 RC bugs suggested. Of course every boot loader failure is critical to the person affected by it, not to mention that GRUB 2 offers more complex functionality than any other boot loader (e.g. LVM and RAID), and so it tends to accumulate RC bugs at rather a high rate. That said, we'd been neglecting its bug list for some time; Robert and Felix have both been taking some time off, Jordi mostly only cared about PowerPC and can't do that any more due to hardware failure, and I hadn't been able to pick up the slack.
Most of my projects at work for the next while involve GRUB in one way or another, so I decided it was a perfectly reasonable use of work time to do something about this; I was going to need fully up-to-date snapshots anyway, and practically all the Debian grub2 bugs affect Ubuntu too. Thus, with the exception of some other little things like releasing the first Maverick alpha, I've spent pretty much the last week and a half solidly trying to get the grub2 package back into shape, with four uploads so far.
The RC issues that remain are:
upgrade-from-grub-legacy problems (#547944, #550477):upgrade-from-grub-legacy, and I should be able to unpick the bugs this way.
mdadm switched its default from the old 0.90 format which GRUB understood. Felix put together a branch implementing the hard parts of this a while back, and I've been trying to finish it off. The hard bit is dealing with device naming, especially as the new-format and rather more useful names under /dev/md/ don't show up during d-i after creating RAID volumes; I think this is because we always create them as /dev/md0 etc. It's looking tractable, though.
grub-install not being properly run (#557425 and many other sub-RC bugs):device.map files (#575076 and other sub-RC bugs):device.map in general. It was fine in the 1990s but it's hopeless now. Unfortunately there are still a small number of problems with running entirely without one, and one of my patches to help is controversial upstream, so we probably won't get to that for squeeze. In the meantime we'll probably just need some extra sanity-checking and robustness in the event that there's an incorrect or out-of-date device.map lying around, which we may just be able to do in the maintainer scripts or something if necessary.
grub-emu on sparc as a workaround.
grub-mkconfig a bit more robust in the event that the root filesystem isn't one that GRUB understands (#561855, #562672), and I'd quite like to write some more documentation.
On the upside, progress has been good. We have multiple terminal support thanks to a new upstream snapshot (#506707), update-grub runs much faster (#508834, #574088), we have DM-RAID support with a following wind (#579919), the new scheme with symlinks under /dev/mapper/ works (#550704), we have basic support for btrfs / as long as you have something GRUB understands properly on /boot (#540786), we have full info documentation covering all the user-adjustable settings in /etc/default/grub, and a host of other smaller fixes. I'm hoping we can keep this up.
If you'd like to help, contact me, especially if there's something particular that isn't being handled that you think you could work on. GRUB 2 is actually quite a pleasant codebase to work on once you get used to its layout; it's certainly much easier to fix bugs in than GRUB Legacy ever was, as far as I'm concerned. Thanks to tools like grub-probe and grub-fstest, it's very often possible to fix problems without needing to reboot for anything other than a final sanity check (although KVM certainly helps), and you can often debug very substantial bits of the boot loader - the bits that actually go wrong - using standard tools such as strace and gdb. Upstream is helpful and I've been able to get many of the problems above fixed directly there. If you have a sound knowledge of C and a decent level of understanding of the environment a boot loader needs to operate in - or for that matter specialist knowledge of interesting device types - then you should be able to find something to do.
At Canonical, we ve started experimenting with Mumble as an alternative to telephone calls for real-time conversations. The operating model is very much like IRC, based on channels within which everyone can hear everyone else as they speak.
Mumble works best with a headset, which offers better audio recording quality due to the proximity of the microphone, and avoids problems with echo and feedback. I like to pace around while I talk, and so I ve already invested in a Plantronics Calisto Pro, which includes a DECT handset, a Bluetooth headset and a nice charging base. My laptop has bluetooth onboard, so I set about trying to get Mumble set up to use the headset via bluetooth.
The first thing I tried was to click on the bluetooth icon on the panel, and select Set up new device.... After setting the headset to pairing mode, I waited quite some time for it to show up in the list, but it never did. After opening the preferences dialog, I discovered that this was (presumably) because I had already paired it, ages ago.
So, I went about trying to get PulseAudio to talk to it. After some hunting, I tried:
pactl load-module module-bluetooth-device address=00:23:xx:xx:xx:xx
Card #1
Name: bluez_card.00_23_XX_XX_XX_XX
Driver: module-bluetooth-device.c
Owner Module: 17
Properties:
device.description = "Calisto PLT"
device.string = "00:23:XX:XX:XX:XX"
device.api = "bluez"
device.class = "sound"
device.bus = "bluetooth"
device.form_factor = "headset"
bluez.path = "/org/bluez/13899/hci0/dev_00_23_XX_XX_XX_XX"
bluez.class = "0x200404"
bluez.name = "Calisto PLT"
device.icon_name = "audio-headset-bluetooth"
Profiles:
hsp: Telephony Duplex (HSP/HFP) (sinks: 1, sources: 1, priority. 20)
off: Off (sinks: 0, sources: 0, priority. 0)
Active Profile: off
pulseaudio[15239]: module-bluetooth-device.c: Default profile not connected, selecting off profile
paplay -d bluez_sink.00_23_XX_XX_XX_XX /usr/share/sounds/alsa/Front_Center.wav





 For various reasons, I chose to leave Ubuntu 10.04 LTS using OpenSSH 5.3p1. The new features in 5.4p1 such as certificate authentication, the new smartcard handling, netcat mode, and tab-completion in sftp are great, but unfortunately it was available just a little bit too late for me to be able to land it for 10.04 LTS. I realise that many Lucid users want to make use of these features for one reason or another, though, so as a compromise here's a PPA containing OpenSSH 5.5p1 for Lucid.
I intend to keep this up to date for as long as I reasonably can, and I'm happy to accept bug reports on it in the usual place.
Note: I wrote most of this before Neil Williams' recent comments on the 3.0 family of formats, so despite the timing this isn't really a reaction to that although I do have a couple of responses. On the whole I think I agree that the Lintian message is a bit heavy-handed and I'm not sure I'm thrilled about the idea of the default source format being changed (though I can see why the dpkg maintainers are interested in that). That said, as far as I personally am concerned, there is a vast cognitive benefit to me in having as much as possible be common to all my packages. Once I have more than a couple of packages that require patching and benefit from the
For various reasons, I chose to leave Ubuntu 10.04 LTS using OpenSSH 5.3p1. The new features in 5.4p1 such as certificate authentication, the new smartcard handling, netcat mode, and tab-completion in sftp are great, but unfortunately it was available just a little bit too late for me to be able to land it for 10.04 LTS. I realise that many Lucid users want to make use of these features for one reason or another, though, so as a compromise here's a PPA containing OpenSSH 5.5p1 for Lucid.
I intend to keep this up to date for as long as I reasonably can, and I'm happy to accept bug reports on it in the usual place.
Note: I wrote most of this before Neil Williams' recent comments on the 3.0 family of formats, so despite the timing this isn't really a reaction to that although I do have a couple of responses. On the whole I think I agree that the Lintian message is a bit heavy-handed and I'm not sure I'm thrilled about the idea of the default source format being changed (though I can see why the dpkg maintainers are interested in that). That said, as far as I personally am concerned, there is a vast cognitive benefit to me in having as much as possible be common to all my packages. Once I have more than a couple of packages that require patching and benefit from the 3.0 (quilt) format as a result, I find it in my interest to use it for all my non-native packages even if they're patchless right now, so that for instance if they need patches in the future I can handle them the same way. It's not unheard of for me to apply temporary patches even to packages I actively maintain upstream, so I don't discount those either. I haven't decided what to do with my native packages yet; unless they're big enough for bzip2 compression to be worthwhile, there doesn't seem to be much immediate advantage to 3.0 (native).
Anyway, on to the main body of this post:
I've been one of the holdouts resisting use of patch systems for a long time, on the basis that I felt strongly that dpkg-source -x ought to give you the source that's actually built, rather than having to mess around with debian/rules targets in order to see it. Now that the 3.0 (quilt) format is available to fix this bug, I felt that I ought to revisit my resistance and start trying to use it. Migrating to it from monolithic diffs is of course a bit more work than migrating to it from other patch systems, so it's taken me a little while to get round to it. I'd been thinking about holding off until there was better integration with revision control (e.g. bzr looms), as I feel that patch files really ought to be an export format, but I eventually decided that I shouldn't let the perfect be the enemy of the good. I have enough experience with co-maintaining packages that use build-time patch systems to be able to compare my reactions.
After experimenting with a couple of small packages, I moved over to the deep end and converted openssh a few weekends ago, since quite a few people have requested over the years that the Debian changes to openssh be easier to audit. This was a substantial job - over 6000 lines of upstream patches - but not actually as much work as I expected. I took a fairly simplistic approach: first, I unapplied all the upstream patches from my tree; then I ran bzr di interdiff -q /dev/stdin /dev/null >x, reduced it to a single logically-discrete patch, applied it to a new quilt patch using quilt fold, and repeated until x was empty. This was maybe an hour or two of work, and then I went through and tagged all the patches according to DEP-3, which took another few hours. After the first pass, I ended up with 38 patches and a much clearer idea of what has been forwarded upstream and what hasn't; I currently have 5 patches to forward or eliminate, down from 18.
Good things:
dpkg-source -x gives you, so it's the natural representation in revision control too), bzr blame works just as you'd expect and displays both upstream and Debian changes at once. I rely on tools like blame a lot, and I really hate the way build-time patch systems make it hard to use revision control when the tree is in a built state, so this was a hard requirement for me..pc directory, and the tree checks out in the patched state (as it should), so I needed some way for developers to get quilt working easily after a checkout. This is sort of the reverse of the previous problem, where users had to do something special after dpkg-source -x, and I consider it less serious so I'm willing to put up with it. I ended up with a rune in debian/rules that ought to live somewhere more common.quilt pop -a, force a merge despite the modified working tree, and then quilt push && quilt refresh -pab until I get back to the top of the stack, modulo slight fiddliness when a patch disappears entirely; thus effectively using quilt's conflict resolution rather than bzr's. I suppose this will serve as additional incentive to reduce my patch count. I know that people have been working on making this work nicely with topgit, although I'm certainly not going to put up with the rest of git due to that; I'm happy to wait for looms to become usable and integrated. :-) Note: I wrote most of this before Neil Williams' recent comments on the 3.0 family of formats, so despite the timing this isn't really a reaction to that although I do have a couple of responses. On the whole I think I agree that the Lintian message is a bit heavy-handed and I'm not sure I'm thrilled about the idea of the default source format being changed (though I can see why the dpkg maintainers are interested in that). That said, as far as I personally am concerned, there is a vast cognitive benefit to me in having as much as possible be common to all my packages. Once I have more than a couple of packages that require patching and benefit from the 3.0 (quilt) format as a result, I find it in my interest to use it for all my non-native packages even if they're patchless right now, so that for instance if they need patches in the future I can handle them the same way. It's not unheard of for me to apply temporary patches even to packages I actively maintain upstream, so I don't discount those either. I haven't decided what to do with my native packages yet; unless they're big enough for bzip2 compression to be worthwhile, there doesn't seem to be much immediate advantage to 3.0 (native).
Anyway, on to the main body of this post:
I've been one of the holdouts resisting use of patch systems for a long time, on the basis that I felt strongly that dpkg-source -x ought to give you the source that's actually built, rather than having to mess around with debian/rules targets in order to see it. Now that the 3.0 (quilt) format is available to fix this bug, I felt that I ought to revisit my resistance and start trying to use it. Migrating to it from monolithic diffs is of course a bit more work than migrating to it from other patch systems, so it's taken me a little while to get round to it. I'd been thinking about holding off until there was better integration with revision control (e.g. bzr looms), as I feel that patch files really ought to be an export format, but I eventually decided that I shouldn't let the perfect be the enemy of the good. I have enough experience with co-maintaining packages that use build-time patch systems to be able to compare my reactions.
After experimenting with a couple of small packages, I moved over to the deep end and converted openssh a few weekends ago, since quite a few people have requested over the years that the Debian changes to openssh be easier to audit. This was a substantial job - over 6000 lines of upstream patches - but not actually as much work as I expected. I took a fairly simplistic approach: first, I unapplied all the upstream patches from my tree; then I ran bzr di interdiff -q /dev/stdin /dev/null >x, reduced it to a single logically-discrete patch, applied it to a new quilt patch using quilt fold, and repeated until x was empty. This was maybe an hour or two of work, and then I went through and tagged all the patches according to DEP-3, which took another few hours. After the first pass, I ended up with 38 patches and a much clearer idea of what has been forwarded upstream and what hasn't; I currently have 5 patches to forward or eliminate, down from 18.
Good things:
dpkg-source -x gives you, so it's the natural representation in revision control too), bzr blame works just as you'd expect and displays both upstream and Debian changes at once. I rely on tools like blame a lot, and I really hate the way build-time patch systems make it hard to use revision control when the tree is in a built state, so this was a hard requirement for me..pc directory, and the tree checks out in the patched state (as it should), so I needed some way for developers to get quilt working easily after a checkout. This is sort of the reverse of the previous problem, where users had to do something special after dpkg-source -x, and I consider it less serious so I'm willing to put up with it. I ended up a rune in debian/rules that ought to live somewhere more common.quilt pop -a, force a merge despite the modified working tree, and then quilt push && quilt refresh -pab until I get back to the top of the stack, modulo slight fiddliness when a patch disappears entirely; thus effectively using quilt's conflict resolution rather than bzr's. I suppose this will serve as additional incentive to reduce my patch count. I know that people have been working on making this work nicely with topgit, although I'm certainly not going to put up with the rest of git due to that; I'm happy to wait for looms to become usable and integrated. :-)Next.